


Consider a situation where you need data quickly in large volume from websites. It is tedious and time consuming to collect data manually. Web scraping makes this procedure much faster and easier.
Purpose of Web Scraping
Data extraction is a method of gathering large volume of data through websites. But this data is useful? Let's discuss several web scraping applications:
- Comparing Prices: data extracting services is useful in extracting data from shopping websites and use them for comparing prices.
- Gathering Email Addresses: data extracting is used by many firms that utilize email as a marketing tool to acquire email addresses and then send mass emails.
- Social Media: Web scraping can be used to extract data through social media sites such as Twitter in order to determine trends.
- R&D Department: Web scraping can be used to gather a significant amount of data for example, temperature, statistics, general information, and so on through websites, which is then processed and used in surveys or research.
- Job Postings: Information about job opportunities and interviews is gathered from several websites and then compiled in one location so it is effortlessly available to user.
How to Define Web Scraping? Is it Legal to Scrape Data?

Data extracting is the process of fetching large volume of data through sites. The data on the webpage is not structured. Web scraping assist in gathering unstructured information and storing them in structured format. There are various methods of
Scraping websites, include using online services, APIs, or developing codes. Now we will discuss web scraping using Python.
When it comes to legal aspects, certain websites permit it while others do not. You may check the "robots.txt" file on a website to see if it enables web scraping or not. By attaching "/robots.txt" to the URL you intend to scrape, you can find this file. For example, to scrape Flipkart website use www.flipkart.com/robots.txt
Web Scraping with Python

Every programing language is excellent and useful as Python. Why to use Python instead of other languages of web scraping?
The following is a list of Python features that makes it unique and can be chosen over other languages:
1. Easy to Use
Python is an easy language to code. There are no curly-braces or semi-colons required anywhere. This makes it easy to use and less confused.
2. Large Pool of Libraries
Python includes a large number of library, such as Matplotlib, Numpy, Pandas, etc. that offer approaches and functions for a several uses. As a result, it's suitable for site scraping and data manipulation.
3. Defined Data Types:
Data types should not be defined for variables using Python. This allows you to save time and helps finishing your work rapidly.
4. Understandable Syntax:
Python language rules is simple and easy to learn, knowing the fact that interpretation of a Python code is rather comparable to understanding a statement of English. The indentation of Python helps users to distinguish between diverse blocks /scopes in code, making it easy-to-read and easy to comprehend.
5. Large Task and Small Code:
Time saving is the main feature of data extracting and you cannot waste more time in writing codes for the tasks. Python solves this problem by allowing to write small codes for large task and hence the time of writing codes is also saved.
6. Community:
Finding difficulties while writing codes? Don’t worry when you have Python. It offers the largest and active communities in which you can seek assistance.
Process of Web Scraping

When web scraping code is executed, the specified request is sent to URL. Data is generated using the requests made, allowing to understand the XML or HTML page. After that the code parses the XML or HTML page, finding data and extracting the same.
Below mentioned is the list of stages involved in web scraping:
- Locate the URL of data to scrape.
- Examining the Page
- Search the information you want to extract
- Codes writing.
- Execute the code to get the data.
- Use appropriate format to store data.
Now let’s see extracting Flipkart website data using Python.
Web Scraping Libraries

Python has many applications and there are different libraries for distinct purpose. The following is the list of libraries used by python:
Selenium:
It is an open-source web developing framework. It's a program that automates browser functions.
BeautifulSoup:
BeautifulSoup is the Python tool that allows you to parse XML and HTML texts. It generates parse trees, which are useful for quickly extracting data.
Pandas:
It is data handling and analysis library and used to fetch information and store in format that you wish.
Let us take an example of scraping Flipkart website data
Pre-Requirements:

Python 2.x and Python 3.x by BeautifulSoup, Selenium, and pandas’ libraries installed
Google-chrome browser
Operating System Ubuntu
Now we will discuss the process,
1. Trace the URL
We will scrape the website of Flipkart to gain the name, price, rating and review of laptops for our example.
https://www.flipkart.com/laptops/buyback-guarantee-on-laptops-/pr?sid=6bo percent 2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU V2 is the URL of the page.
2. Examining the Web Page
In most cases, the data is nested into tags. So that we can study a website to determine the data to be extracted is nested in which tag. Right-click an element and choose "Inspect" from the pull-down menu.
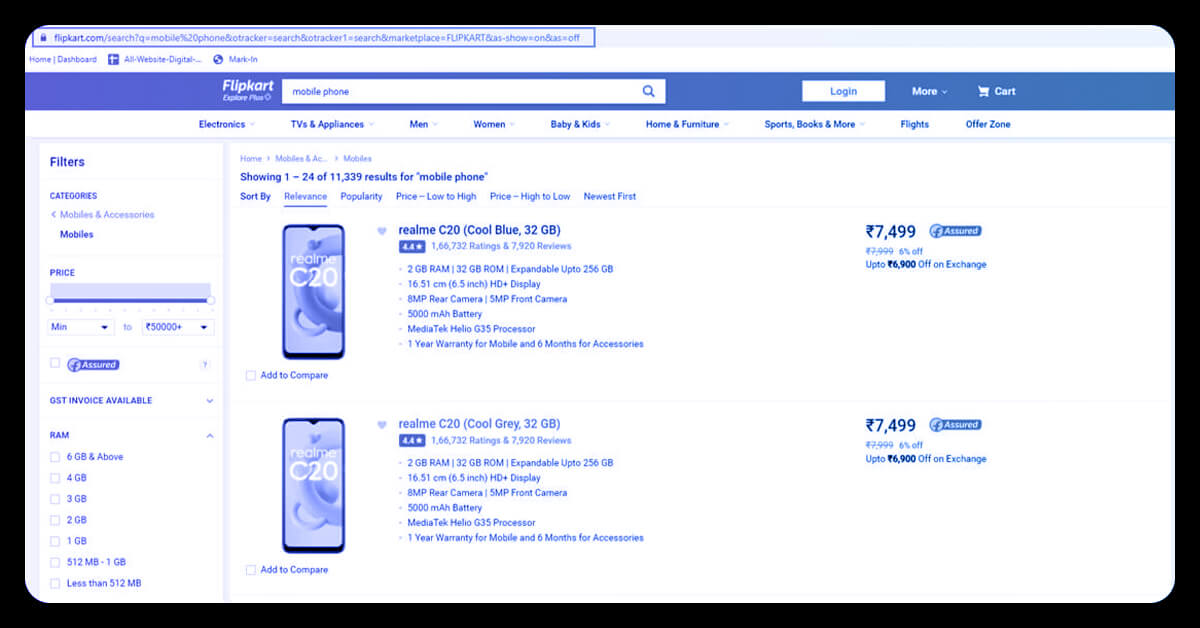
When you select "Inspect" tab, a “Inspector Box" shall appear.
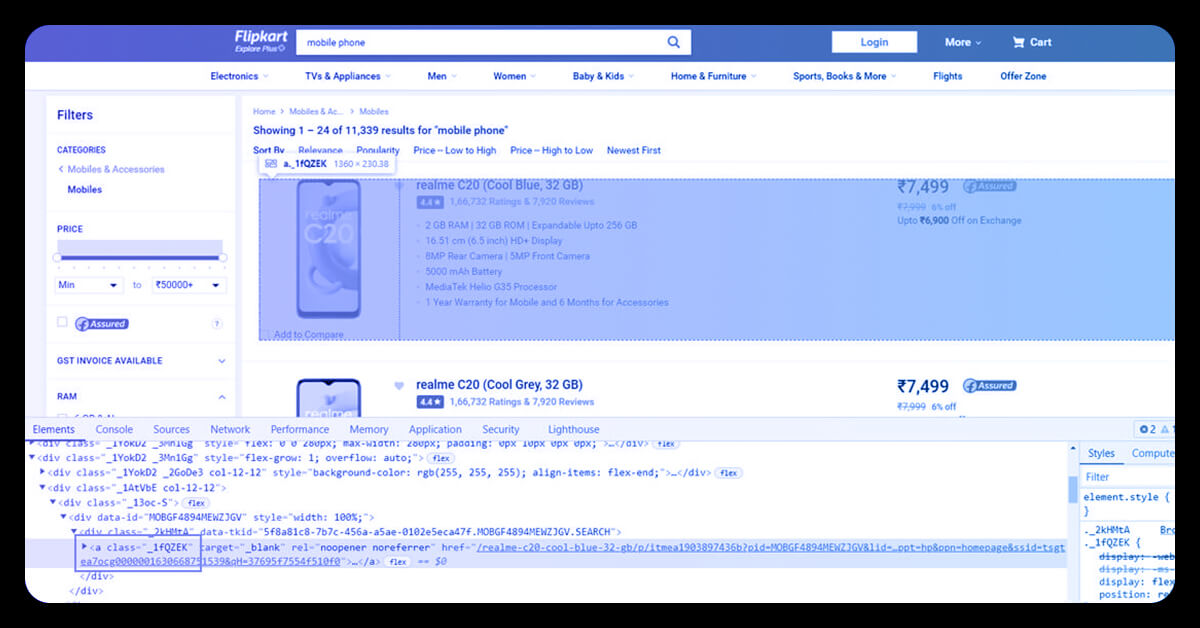
3. Trace the Data to Be Retrieved
Let's take a look at the Name, Price, and Rating tags that are all nested within "div" tag.
4. Compose the Program
Let's start by building a file of Python. For doing this, open Ubuntu's terminal and write gedit < file name> with the extension.py.
My file will be called "web-s." The command is as follows:
gedit web-s.py
let’s write codes for the file.
All the relevant libraries to be imported:
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
Chrome browser is used to configure web driver and set a path for chrome driver.
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
Below mentioned are the codes to open URL:
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&amp;uniqBStoreParam1=val1&amp;wid=11.productCard.PMU_V2")
Now we will extract data from websites after creating codes to open URL. The information you wish to fetch is nested into div tags. These div tags will fetch data, class names and to be saved in variable. see code:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
5. Execute Code and Retrieve the Information
Use the following to execute code:
python web-s.py
6. The Data to Be in the Proper Format
You wish to save data in desired format after you've extracted it. Based on needs, the format will differ. We will save the fetched information in CSV format for this example. The below lines to be used in the code for storing the data:
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})df.to_csv('products.csv', index=False, encoding='utf-8')
Now, we will run the code again.
The file name products.csv is made and this file contains the data extracted.
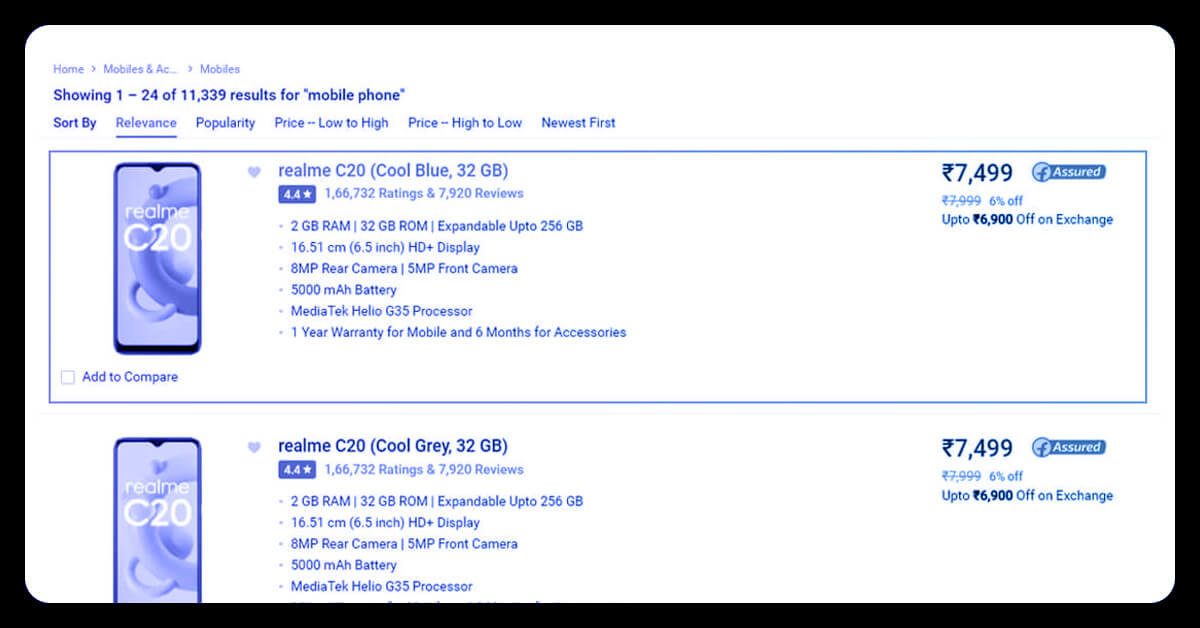
Conclusion
Hence this was all about scraping Flipkart data with Python. You can use different libraries, extract the required data, store the data for further analysis.
Get in touch with us to extract Flipkart data using Python.
Contact Web Screen Scraping today!
Request for a quote!










