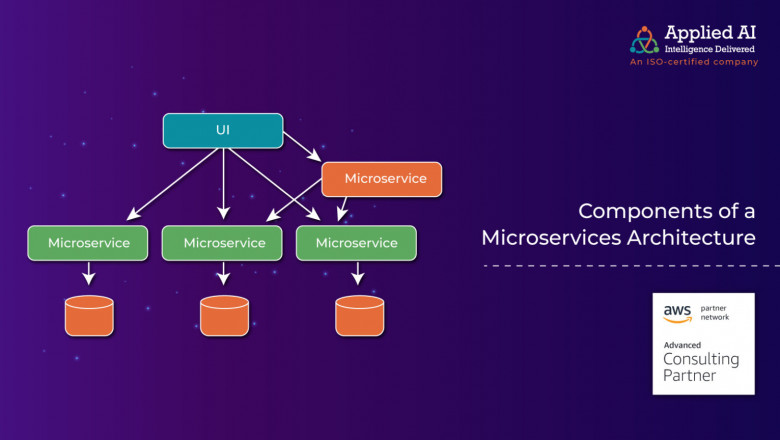
As one might guess from its name, microservices describe an architecture that is small. It manages this by breaking up large monolithic applications into individual, and independent services that are managed by discrete teams. Each service includes all the elements it needs to run in any environment, including code, databases, application functions, and programming logic, and spreads it across servers and platforms.
To do all this effectively, the microservices architecture requires certain components that help bring all these entities together cohesively across a distributed system. The most important of these components are as follows:

Containers
Although this might sound paradoxical, containers are actually not necessary for deploying microservices; nor are microservices the only reason containers exist. What makes them vital is that they have the ability to significantly improve deployment, save time, and enhance app efficiency, compared to other deployment methods such as Virtual Machines (VM)
The biggest point of differentiation between containers and VMs is that a VM needs a dedicated Operating System (OS) for its use, whereas many containers can share an OS and middleware components. Eliminating VMs eliminates the need to provide individual OS for each small service. This means organizations can run a larger collection of microservices on a server.
The second significant advantage of using containers in microservices is that they offer the ability to on-demand deployment, without compromising application performance.
Containers orchestration can also be automated, this enables configuring, scheduling, management, provisioning, deployment, scaling, and health monitoring of individual containers to be undertaken with minimal effort. There are several container orchestration tools; the most popular of which are Docker (aka, Docker Swarm), an open-source platform for container management, Kubernetes, OpenShift, and Google Container Engine (GKE), among others.
Containers in microservices, thus, enable independence and consistency, which is a critical part of scaling pieces of a microservices architecture — depending on workloads — as opposed to the whole application. In the event of a failure, containers support the ability to redeploy microservices.
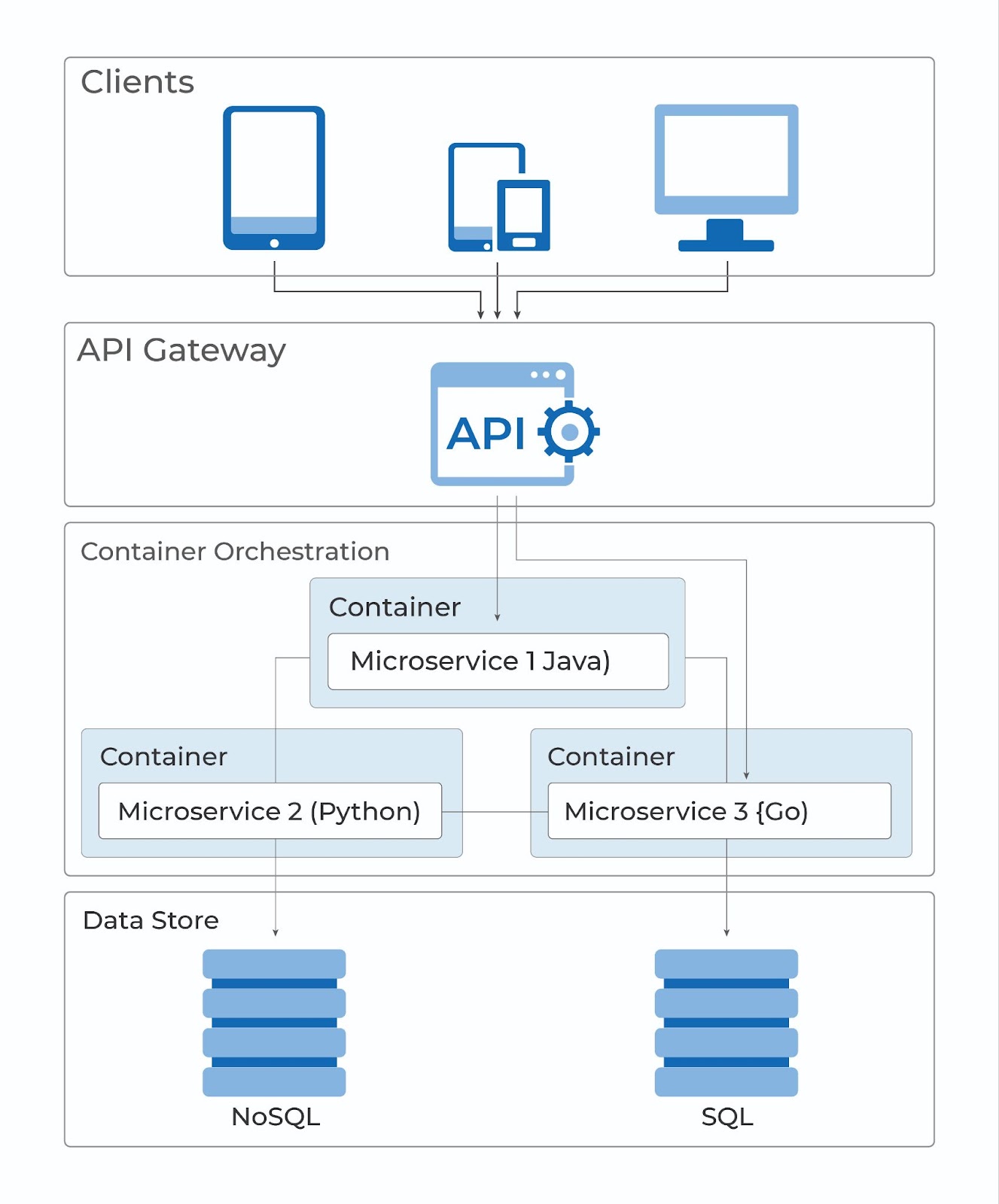
Service Discovery (Service Registry)
Unlike in a monolithic application, microservices architectures comprise several smaller applications that work individually to deliver a collectively larger solution. This allows for many big benefits, including rapid and economical scaling—since only individual microservices need to be scaled rather than the entire application itself—quick deployment, monitoring, etc. But to function, the microservices that comprise this architecture must be able to communicate; i.e. call on other microservices as needed. This means they must know where the particular service is deployed. Enter, Service Discovery! Service Discovery is a microservice in itself, and its function is to maintain a register (service registry) of where all the microservices are located. So in one sense, this is actually a service location discovery.
Service discovery patterns:
There are two basic discovery patterns: the client-side pattern and the server-side pattern
The client-side discovery pattern: Consider an analogy here. Say you want to order out from a certain restaurant but don’t know their number. So you call up directory services (or Google), get the number, and make the call. In this instance directory services (or Google) acts as the service registry, and you are the client. This is known as client-side discovery. The pattern basically searches the service registry to locate the required service, sends the information back to the client service, and then routes the request from the client to the required service, maybe, using a load balancing algorithm.
The server-side pattern: In a server-side discovery pattern, using the above analogy, you—the client—call up Google, which searches the service registry AND forwards your request directly to the applicable service instance.
It is important that the service registry data should always be current, in order for services to find their related service instances at runtime. If the service registry is down, the entire inter-service communication will crash and so with the app. To avoid this, enterprises typically use a distributed database.
Service Mesh
As microservices grow in features and maturity, they also grow in complexity, with more and more microservices ‘talking’ to each other to deliver a cohesive user experience. But this also means there are many more endpoints and interactions to monitor, secure, and scale. This translates into increased security vulnerability with higher debugging effort and time. Service Mesh addresses this need. Acting at the application level, the service mesh handles service-to-service communication for cloud applications. It overlays existing applications, without them needing to be aware of its existence. It comprises a Data Plane and a Control Plane. The data plane attaches small proxies to each service, these are called sidecars and their job is to handle incoming and outgoing traffic between services.
The control plane manages service-to-service communications, security policies, and monitoring.
The control plane manages and configures proxies to route traffic, and also collects telemetry data to help monitoring
Service meshes eliminate a lot of the manual effort needed for services to interact. As your applications continue to grow, meshes work to maintain infrastructure and ensure that communication doesn’t break down. This makes it easier for DevOps teams to manage Cloud Native Applications (CNA) in hybrid or multi-cloud environments.
Service meshes contain the logic governing communications. Since the logic is in individual services, it increases the portability of individual microservices. They can be moved to a new server, Docker/K9 cluster or a different public cloud platform, without needing to rebuild the application.
By enforcing security policies and managing access (with encryption, where required) and authentication across the environment, service meshes reduce the potential for cyber attacks.
Read also, Monolithic vs microservices architecture (link to article #3)
API Gateway
Microservices are disconnected autonomous services that together make up the entire application (unlike a monolithic app). This means that to deliver the desired user experience the services need to communicate with the outside client, and occasionally with each other. And they do that through an API gateway. API gateways create an abstraction layer between microservices and outside clients.
The API gateway’s main functions center around communication and administrative roles—such as authenticating, caching, and managing requests, as well as monitoring, messaging and even performing load balancing (which typically occurs within a monolithic application). Thus API gateways allow microservices to remain lightweight.
Since services are autonomous they are basically polyglots, in that they are free to use different technology stacks. An API gateway synergizes this by standardizing messaging protocols, thus speeding up communication between microservices and clients and freeing both the client and the service from the task of translating requests written in unfamiliar formats.
In addition, most API gateways also provide built-in security features, which allow them to manage authorization and authentication for microservices, as well as tracking incoming and outgoing requests to identify any possible intrusions.
There are many API gateway options—both open source and proprietary, e.g. from cloud providers such as Azure and AWS—available to choose from.
Applied AI offers an easy-to-use Serverless API generator that comes with clear instructions to set up, configure and secure. The SLS API Generator can be used with a CLI-based approach, or an API-based approach, which enables configuration and development of APIs without the time- and effort-intensive task of writing production code for the API.
Benefits include:
Speedy development/integration
Ease in modifying code, as per entity definition
Use of pre-written test cases to save unit testing time
Code uniformity, standardization (standard libraries)
Lean code that conforms to DRY norms, and coding best practices
For step by step instructions on how to set up, configure and secure your API gateway using the SLP API generator, reach out to our team, today.