

We have searched for many things on the internet. All the information is quickly accessible but could not be saved very easily so that we can utilize it later for all other objectives.
One way is copying data manually as well as saving that on the desktop. Although, it consumes a lot of time. Web scraping could be useful in these cases.
What is Web Scraping?
Web scraping is the method utilized to scrape a huge amount of data from different websites as well as the store that in the computer. The data could be later utilized for analysis.

Here, we will exhibit to you how to extract reviews of any particular product from Amazon using Python.
The initial step is checking if a website helps in scraping data or not. It could be checked by adding robots.txt after a website link given here.
https://www.amazon.in/robots.txt
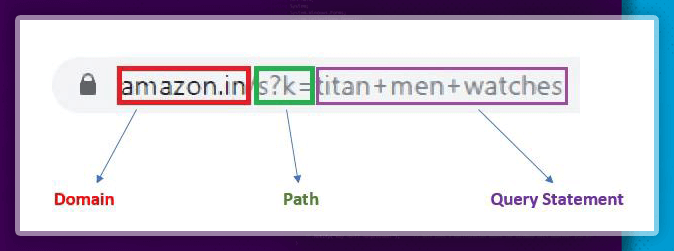
The URL could be split into five parts like protocol, path, domain, query-string, as well as a fragment. However, we would be concentrating largely on 3 parts like domain, path, as well as a query string.
STEPS:
- Find the page URL to get scrapped.
- Check the page elements as well as identify the required tags.
- Access this URL.
- Get elements from the necessary tags.
Let us start coding now!!

We start by importing the given two libraries. Different library requests are used for getting the web page content. We send the request to a URL as well as get the reply. The reply will have the status code together with the content of a web page. BeautifulSoup changes the page contents into a suitable format.
Headers and Cookies
Usually, Python requests do not require headers as well as cookies. However, in a few situations, while we ask for any page content, we have the status code 503 or 403. It means we just cannot use a web page’s content. In those cases, we add cookies and headers to the arguments of requests.get() function.
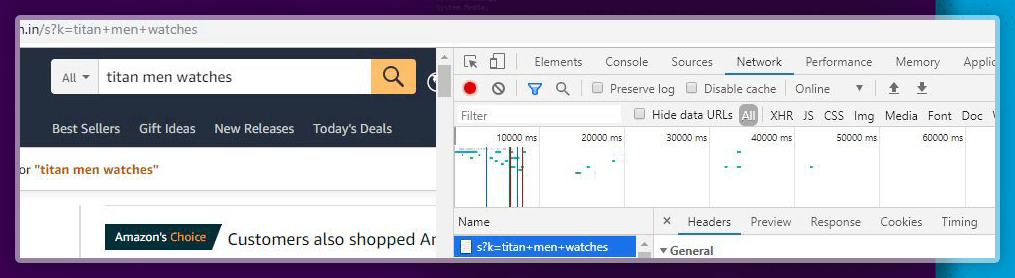
To get the cookies and headers, go to Amazon’s website as well as search for any particular product. After that, just right-click on any element and choose Inspect (or utilize shortcut key - Ctrl+Shift+I). Using the Network tab, it’s easy to find cookies and headers.
Note: Never share any cookies with anybody.
A function can be used for getting page content as well as status code to the needed query. The status code of 200 is needed to continue with the procedure.
def getAmazonSearch(search_query):
url="https://www.amazon.in/s?k="+search_query
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
Extracting Product Names as well as ASIN Numbers
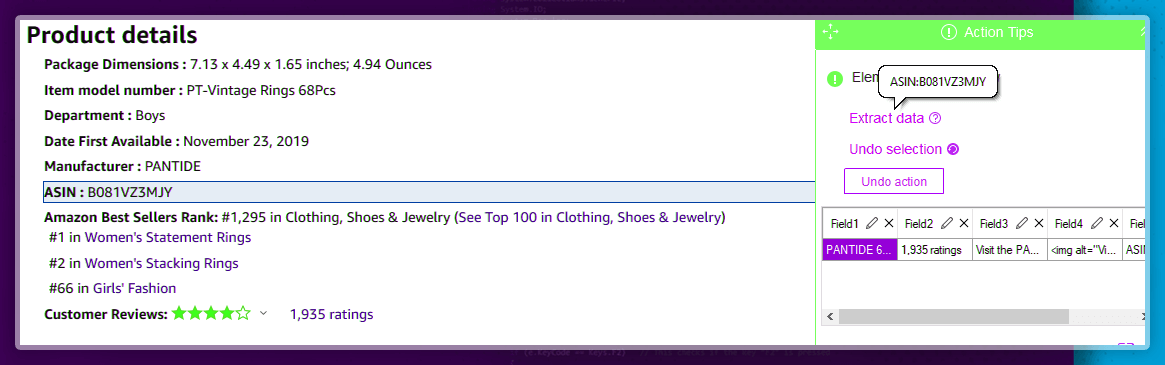
All products in Amazon have unique identification numbers. These numbers are called ASIN (Amazon Standard Identification Number). Using an ASIN number, you can directly use every separate product.
The given function could be used for scraping product names as well as ASIN numbers.
data_asin=[]
response=getAmazonSearch('titan+men+watches')
soup=BeautifulSoup(response.content)
for i in soup.findAll("div",{'class':"sg-col-4-of-24 sg-col-4-of-12 sg-col-4-of-36 s-result-item sg-col-4-of-28 sg-col-4-of-16 sg-col sg-col-4-of-20 sg-col-4-of-32"}):
data_asin.append(i['data-asin'])
The findall() function can be used for finding all the HTML tags of necessary span, attribute, as well as values as given in an argument. All these parameters of the tag would be similar for all product names as well as ASIN right through different product pages. We have just added the data- ASIN part of the content to the new list. With this list, it’s easy to access separate data-ASIN numbers as well as their separate pages.
Scrape Customer Reviews’ Links
Customer reviews would be available on every product page. However, they are only a few. We need different customer reviews for products. Therefore, we need to extract ‘see different customer reviews’ link.
For doing so, we initially define the function that would go to the pages of all products using an ASIN number.
def Searchasin(asin):
url="https://www.amazon.in/dp/"+asin
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
Now, we perform the similar thing because we perform for the ASIN numbers. We scrape all ‘see customer reviews’ links for every product with corresponding HTML tags as well as add href part of the new list.
link=[]
for i in range(len(data_asin)):
response=Searchasin(data_asin[i])
soup=BeautifulSoup(response.content)
for i in soup.findAll("a",{'data-hook':"see-all-reviews-link-foot"}):
link.append(i['href'])
Scraping All the Customer Reviews

Now, we need different links for all products. Using the links, we could extract all reviews of all products. Therefore, we describe a function that will scrape all the product reviews.
def Searchreviews(review_link):
url="https://www.amazon.in"+review_link
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
We utilize the given function to scrape different customer reviews as well as store that in the list.
reviews=[]
for j in range(len(link)):
for k in range(100):
response=Searchreviews(link[j]+'&pageNumber='+str(k))
soup=BeautifulSoup(response.content)
for i in soup.findAll("span",{'data-hook':"review-body"}):
reviews.append(i.text)
We could access details about product pages by adding ‘&page=2 or 3 or 4... .’ for search query as well as repeating steps from extracting ASIN numbers.
Save Reviews in the CSV File
Now, we have extracted all different reviews, so we need to save that in the file to do more analysis.
rev={'reviews':reviews} #converting the reviews list into a dictionary
review_data=pd.DataFrame.from_dict(rev) #converting this dictionary into a dataframe
review_data.to_csv('Scraping reviews.csv',index=False)
We convert the review list into the dictionary. After that, import Pandas library as well as utilize it to convert dictionary in the data frame. After that with to_csv() function then we convert that into the CSV file as well as store that in the computer.
For more information about scraping Amazon customer review data, contact ReviewGators or ask for a free quote!










